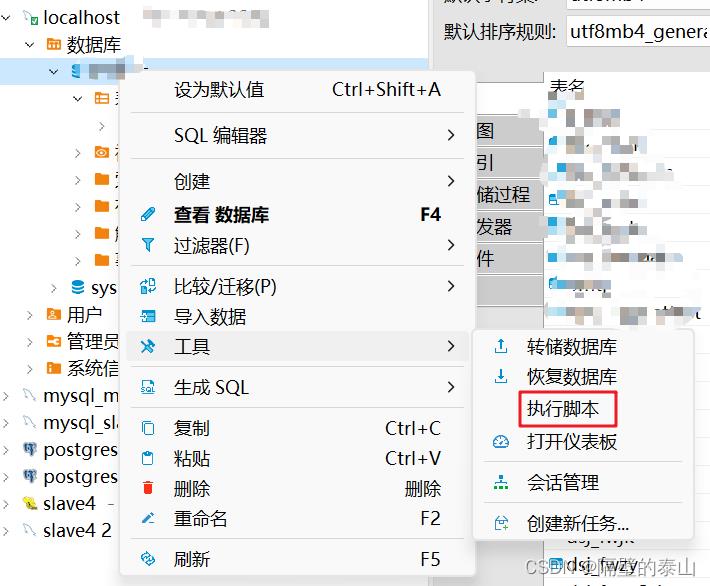
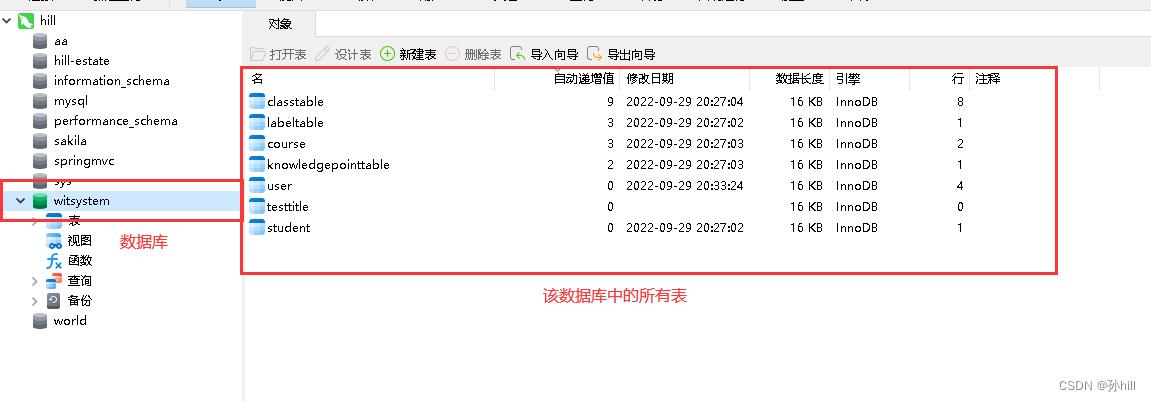
DBeaver执行外部sql文件详细图文教程 T1:DBeaver执行外部sql文件如果数据库已经存在了,那么直接右击库名,如下图:如果数据库不存在,外部sql文件中含有建库语句,可以先手动建库,再把sql文件中建库语句删了后执行脚本。这种方法比较麻烦,直接执行sql脚本的方法如下:先 数据库 2023年09月27日 265 点赞 0 评论 195 浏览
把Navicat中数据库所有表导出的方法 如何把Navicat中的数据库中的所有表导出导入一个数据库的所有表第一步 打开navicat 找到你想要导出表的数据库第二步 右击该数据库,选择转储SQL文件再选择结构和数据… 保存到一个你知道的文件夹中,就ok了。第三步 运 数据库 2023年09月27日 647 点赞 0 评论 959 浏览
mysql与MongoDB性能对比,哪个更适合自己 目录一、简单介绍1、关系型数据库-MySQL2、非关系型数据库-MongoDB4、MongoDB优势与劣势4、MongoDB和MySQL的对比(区别介绍)二、 设计思想的不同三、性能四、数据安全性五、事务六、扩展性简单主从哨兵模式综上所述, 数据库 2023年09月27日 627 点赞 0 评论 1015 浏览
mongoDB和mysql对比分析及选择(详细版) 目录一、前言为什么调研MongoDB?优点:缺点:二、压测性能对比1、准备条件2、百万、千万级别的下不同查询量不同并发量的压测结果3、亿级别的下不同查询量不同并发量的压测结果三、Mysql和MongoDB内存结构1、InnoDb内存使用机制 数据库 2023年09月27日 427 点赞 0 评论 118 浏览
如何在Navicat新建连接、新建数据库以及导入数据库 目录1. 新建连接2. 新建数据库3. 导入数据库总结1. 新建连接新建一个MySQL连接:打开Navicat,点击“左上角第一个图标 --> MySQL”。其他的信息都是自动出现的,只需填写连接名和密码后点击保存, 数据库 2023年09月27日 614 点赞 0 评论 944 浏览
时序数据库VictoriaMetrics源码解析之写入与索引 目录一. 存储格式二. 整体流程三. 写入代码1.入口代码2.写入流程的代码3.写index4. 生成TSID5. 创建index items6. index items存入内存shards一. 存储格式下图是向VictoriaMetric 数据库 2023年09月27日 918 点赞 0 评论 963 浏览
2023年最新Navicat永久激活安装使用教程 2023年最新Navicat激活安装使用教程推荐教程:Navicat for SQLite安装使用教程 附安装包Navicat Premium15安装及破解教程详解亲测有效(附破解失败解决方案)Mac系统Navicat的安装与使用教程Nav 数据库 2023年09月27日 412 点赞 0 评论 1073 浏览
Doris 数据模型ROLLUP及前缀索引官方教程 目录基本概念Aggregate 模型(聚合模型)示例1:导入数据聚合示例2:保留明细数据示例3:导入数据与已有数据聚合Uniq 模型(唯一主键)Duplicate 模型(冗余模型)ROLLUPAggregate 和 Uniq 模型中的 RO 数据库 2023年09月27日 994 点赞 0 评论 722 浏览
Doris实时多维分析的解决方案详解 目录正文限制数据存储结构Aggregate 模型Uniq模型Duplicate 模型数据模型的选择建议前缀索引物化视图(rollup)ROLLUP 调整前缀索引ROLLUP 的几点说明分区和分桶稀疏索引和 Bloom FilterBroad 数据库 2023年09月27日 877 点赞 0 评论 585 浏览
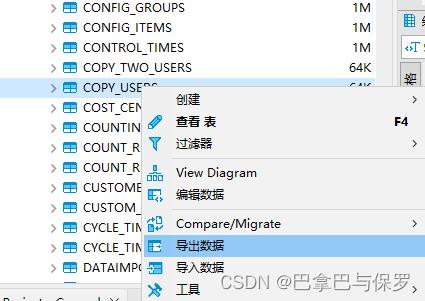
Dbeaver做数据迁移的详细过程记录 目录1、选择源头数据库的表、鼠标右击、选择导出数据2、在数据转化弹框中,双击 ‘数据库,数据表’ 那一栏3、选择目标数据库,调整字段类型映射关系4、调整字段的映射关系5、勾选‘打开新连接’,& 数据库 2023年09月27日 432 点赞 0 评论 240 浏览
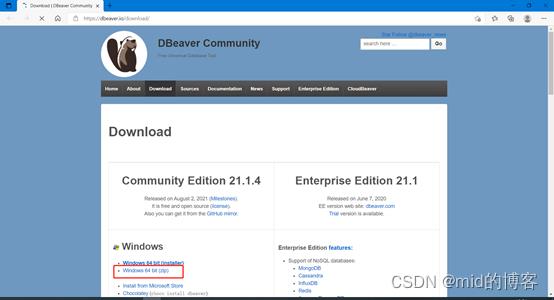
dbeaver工具连接达梦数据库的完整步骤 目录一 概述二、环境准备2.1 DBeaver可以绿色版安装,下载zip包解压即可使用2.2、解压完成后运行dbeaver.exe2.3、选择“数据库”-“驱动管理器”,然后点击“ 数据库 2023年09月27日 788 点赞 0 评论 300 浏览
快速解决openGauss数据库pg_xlog爆满问题 问题现象最近有一个之前搭的环境登不上了,好久没用想拿来测试的时候发现启动不了。启动时报错:[Errno 28] No space left on device query也不行了,提示没有空间了。查询磁盘使用情况 df -h ,果然100% 数据库 2023年09月27日 531 点赞 0 评论 256 浏览
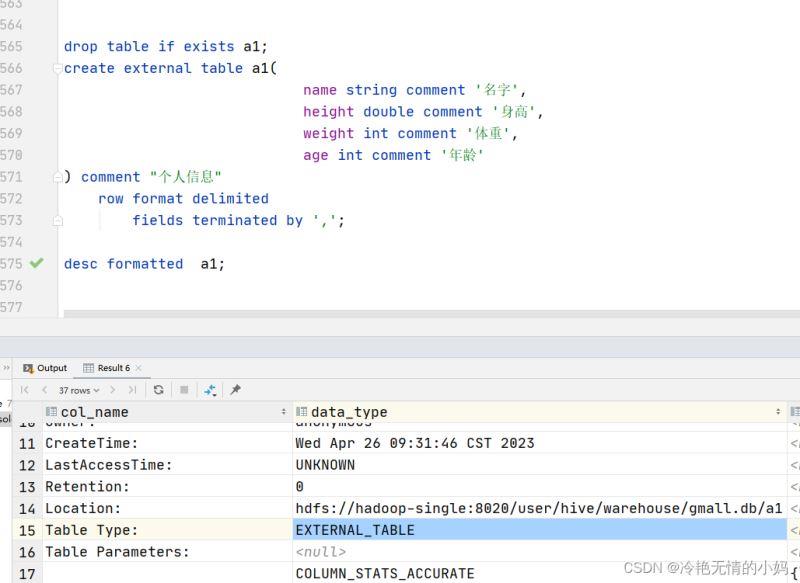
hive内部表和外部表的区别详解 Hive内部表:默认创建的表是内部表。hive完全管理表(元数据和数据)的声明周期,类似于RDBMS的表。当删除表时,他会删除源数据以及表的元数据。Hive外部表:外部表的数据不是Hive拥有或者管理的,只管理元数据的声明周期。要创建一个外 数据库 2023年09月27日 652 点赞 0 评论 553 浏览
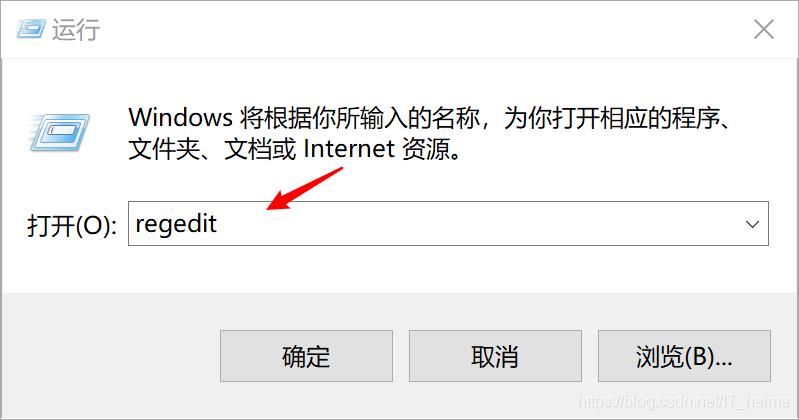
如何查看Navicat加密的数据库密码 目录查看Navicat加密的数据库密码1、打开运行窗口,输入regedit,点击确认按钮,打开注册表编辑器2、在注册表中找到Navicat加密后的密码3、打开PHP在线运行工具,粘贴解密代码4. 修改倒数第三行NavicatPassword 数据库 2023年09月27日 203 点赞 0 评论 377 浏览
Hive数据导出详解 目录一、数据导出是什么?二、六大帮派1.insert2.Hadoop命令导出到本地3.Hive shell命令导出4.export导出到HDFS上5.Sqoop导出6.清除表中的数据(Truncate)——删库跑路总 数据库 2023年09月27日 417 点赞 0 评论 659 浏览
数据库之Hive概论和架构和基本操作 目录Hive概论Hive架构Hive安全和启动Hive数据库操作Hive内部表操作-数据添加Hive内部表特点Hive外部表操作Hive表操作-分区表Hive概论Hive是一个构建在Hadoop上的数据仓库框架,最初,Hive是由Faceb 数据库 2023年09月27日 761 点赞 0 评论 583 浏览
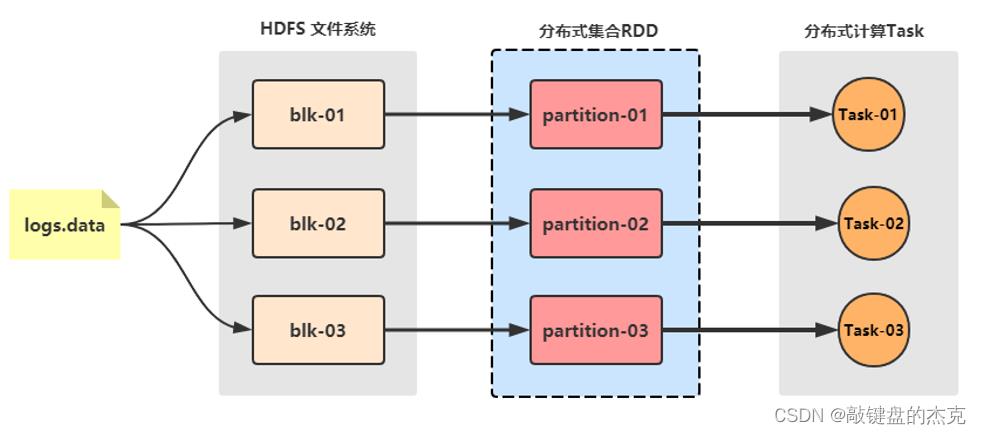
Spark SQL小文件问题处理 目录1.1、小文件危害1.2、产生小文件过多的原因1.3、如何解决这种小文件的问题呢?1.3.1、调优参数1.1、小文件危害大量的小文件会影响Hadoop集群管理或者Spark在处理数据时的稳定性:1.Spark SQL写Hive或者直接写 数据库 2023年09月27日 215 点赞 0 评论 297 浏览
大数据之Spark基础环境 目录前言一、Spark概述(一)Spark是什么(二)Spark的四大特点(三)Spark的风雨十年(四)Spark框架模块(五)Spark通信框架总结前言本篇文章开始介绍Spark基础知识,包括Spark诞生的背景,应用环境以及入门案例等 数据库 2023年09月27日 539 点赞 0 评论 680 浏览
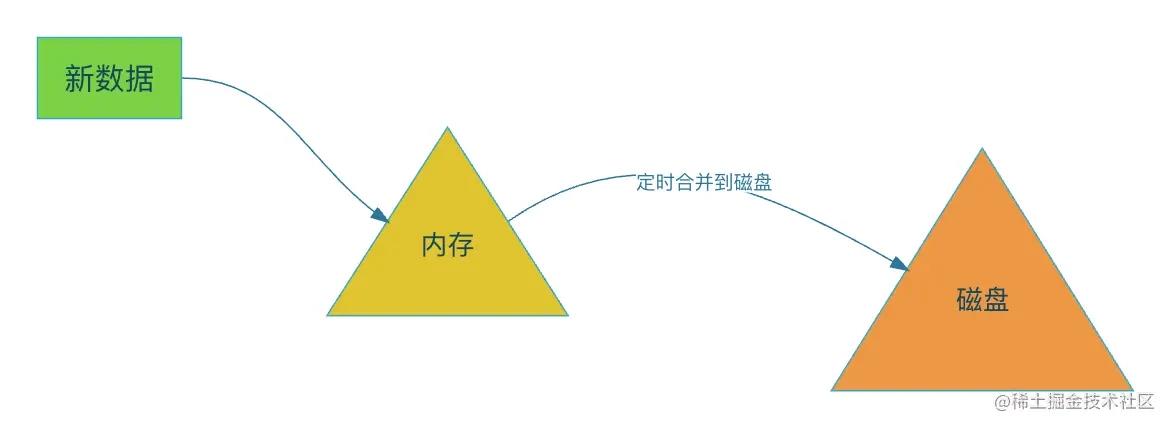
问哭自己lsm 索引原理深入剖析 目录lsm简析提问开始lsm 小结看看与b+tree的区别lsm简析lsm 更像是一种设计索引的思想。它把数据分为两个部分,一部分放在内存里,一部分是存放在磁盘上,内存里面的数据检索方式可以利用红黑树,跳表这种时间复杂度低的数据结构进行检索 数据库 2023年09月27日 602 点赞 0 评论 444 浏览
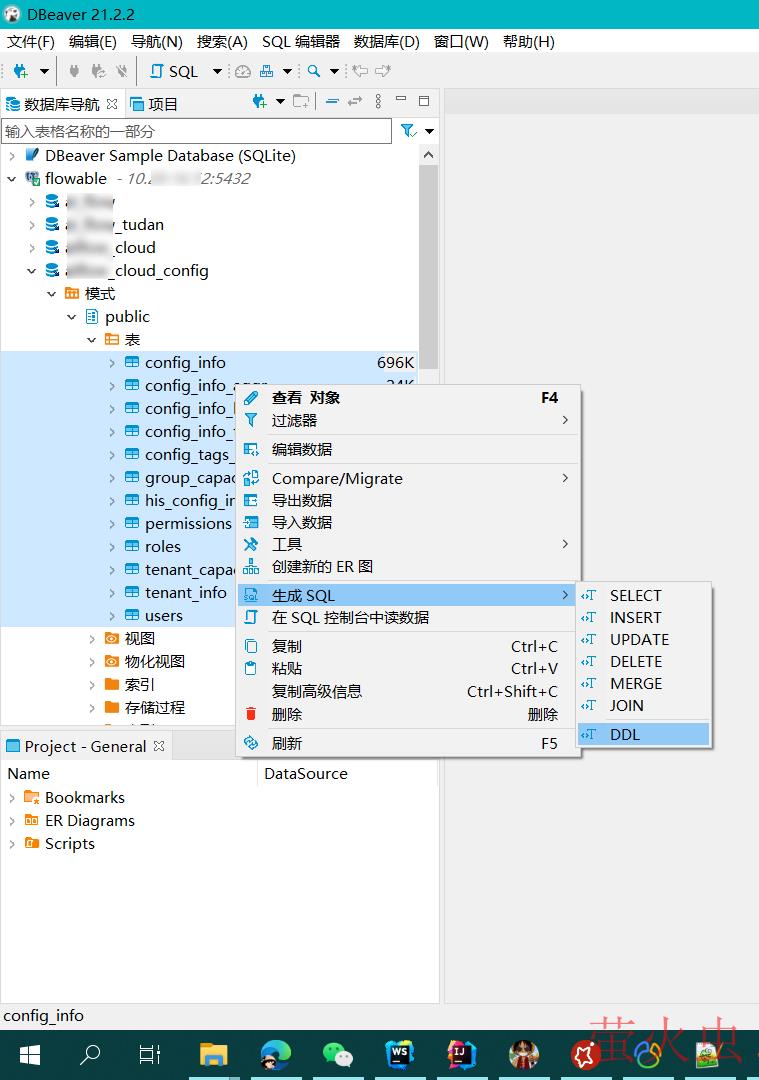
DBeaver之如何导出数据库结构和数据 目录一、导出表结构二、导出序列三、导出表数据总结一、导出表结构1、选择需要导出的表(可多选),右键“生成 SQL”——“DDL”2、复制生成的 SQL 即可,根据需要勾 数据库 2023年09月27日 841 点赞 0 评论 528 浏览